Guide complet pour le web scraping avec Python en 2025


Le web scraping joue un rôle crucial dans la collecte de données sur Internet. Vous pouvez extraire des informations précieuses à partir de divers sites, ce qui facilite l'analyse et la prise de décisions éclairées. En 2025, 84% des développeurs préfèrent Python 3 pour cette tâche. Pourquoi ce choix ? Python se distingue par sa simplicité et sa polyvalence. Il offre une courbe d'apprentissage douce, idéale pour les débutants. De plus, sa documentation complète vous guide dans vos projets de web scraping comment extraire donnees structurees pages web.
En somme, Python n'est pas seulement un langage de programmation ; c'est un outil puissant pour automatiser le web scraping et transformer des données brutes en informations exploitables.
Points Clés
Le web scraping est important pour obtenir des données en ligne. Cela aide à faire de bons choix dans différents domaines.
Python est le meilleur langage pour le web scraping. Il est facile à utiliser et très flexible. C'est parfait pour les débutants.
Pour bien faire du web scraping, suivez ces étapes : trouvez la source, regardez la structure de la page, et utilisez des outils comme Beautiful Soup ou Scrapy.
Pensez aux règles éthiques et légales quand vous scrapez. Respectez les droits d'auteur et demandez la permission si possible.
Pratiquez souvent le web scraping pour devenir meilleur. Chaque projet vous aidera à mieux comprendre cette technique utile.
Introduction au web scraping
Le web scraping est une technique qui vous permet d'extraire des données à partir de sites web. Cette méthode devient de plus en plus populaire dans divers secteurs. En 2025, les statistiques montrent que vous pouvez scrapper jusqu'à 150 sites et 9 000 pages dynamiques chaque semaine. Ces pages proviennent de plusieurs pays, y compris les États-Unis, l'Australie et la France. En utilisant une adresse IP spécifique pour chaque page, vous simulez le comportement d'un utilisateur classique. Cela optimise également les coûts opérationnels, réduisant les dépenses par quatre grâce à une gestion efficace des charges du serveur.
Pourquoi devriez-vous vous intéresser au web scraping ? Voici quelques raisons :
Commerce : Comparez les prix des produits et les avis des clients.
Marketing : Créez des listes de contact pour différents types de clients.
Veille Concurrentielle : Surveillez les activités de vos concurrents.
Analyse de Marché : Étudiez les tendances et les évolutions du marché en temps réel.
Recherche Académique : Collectez de grandes quantités de données pour des études approfondies.
Médias et Journalisme : Extrayez des données pour créer des articles basés sur des faits et des statistiques à jour.
Le web scraping est devenu indispensable pour l'analyse des données sportives. Il permet une collecte efficace d'informations à grande échelle. Les entreprises utilisent également cette technique pour suivre les lancements de produits et les campagnes marketing de leurs concurrents. Cela leur permet de réagir rapidement aux évolutions du marché et de renforcer leur position compétitive.
En somme, le web scraping comment extraire donnees structurees pages web est une compétence précieuse. Elle vous aide à transformer des données brutes en informations exploitables. En maîtrisant cette technique, vous pouvez améliorer votre prise de décision et votre stratégie commerciale.
web scraping comment extraire donnees structurees pages web
Pour extraire des données structurées à partir de pages web, vous devez suivre plusieurs étapes clés. Ces étapes vous aideront à transformer des informations brutes en données exploitables. Voici comment procéder :
Identifier la source de données : Choisissez le site web dont vous souhaitez extraire les données. Assurez-vous que les informations sont accessibles et que vous respectez les conditions d'utilisation du site.
Analyser la structure de la page : Utilisez des outils comme les inspecteurs d'éléments de votre navigateur pour comprendre la structure HTML de la page. Cela vous permettra de localiser les données que vous souhaitez extraire.
Utiliser des bibliothèques Python : Des bibliothèques comme Beautiful Soup et Scrapy facilitent l'extraction de données. Beautiful Soup vous aide à naviguer dans le code HTML, tandis que Scrapy est un framework complet pour le web scraping.
Écrire le code de scraping : Rédigez un script Python qui utilise les bibliothèques choisies pour extraire les données. Voici un exemple simple :
import requests from bs4 import BeautifulSoup url = 'https://example.com' response = requests.get(url) soup = BeautifulSoup(response.text, 'html.parser') for item in soup.find_all('div', class_='data'): print(item.text)Stocker les données : Une fois que vous avez extrait les données, vous pouvez les stocker dans un format structuré comme CSV ou JSON. Cela facilite leur analyse ultérieure.
Des études montrent que le web scraping peut avoir un impact significatif sur les entreprises. Par exemple, une PME industrielle a augmenté son trafic qualifié de 45 % en six mois grâce à une stratégie d'inbound marketing. De même, un équipementier aéronautique a réduit les non-conformités de 30 % après l'intégration d'un logiciel de gestion. Ces résultats illustrent l'importance de maîtriser le web scraping comment extraire donnees structurees pages web.
En suivant ces étapes, vous pouvez efficacement extraire des données structurées et les utiliser pour vos projets. Le web scraping est une compétence précieuse qui vous permet de transformer des données brutes en informations exploitables.
Outils et bibliothèques Python

Pour réaliser un web scraping efficace, vous devez utiliser des outils et des bibliothèques adaptés. Python offre plusieurs options qui simplifient cette tâche. Voici quelques-unes des bibliothèques les plus populaires :
Beautiful Soup : Cette bibliothèque est idéale pour des tâches de scraping simples. Elle facilite le parsing du HTML et vous permet d'extraire rapidement des données. Vous pouvez l'utiliser pour des projets de petite envergure sans trop de complexité.
Scrapy : Si vous travaillez sur des projets plus complexes, Scrapy est la solution. Ce framework robuste vous aide à gérer des sites web avec une structure évolutive. Il est parfait pour extraire des données de plusieurs pages à la fois.
Selenium : Pour les sites dynamiques, Selenium est recommandé. Cette bibliothèque simule l'interaction d'un utilisateur avec le site. Vous pouvez l'utiliser pour cliquer sur des boutons ou remplir des formulaires, ce qui est essentiel pour accéder à certaines données.
Ces outils vous permettent de réaliser un web scraping comment extraire donnees structurees pages web de manière efficace. En choisissant la bonne bibliothèque, vous optimisez votre processus d'extraction de données.
Voici un tableau récapitulatif des bibliothèques :
Bibliothèque | Utilisation | Avantages |
|---|---|---|
Beautiful Soup | Scraping simple | Facilité d'utilisation |
Scrapy | Projets complexes | Structure robuste et évolutive |
Selenium | Sites dynamiques | Simulation d'interaction utilisateur |
En utilisant ces outils, vous pouvez transformer des données brutes en informations exploitables. Cela vous aide à prendre des décisions éclairées dans vos projets.
Étapes pratiques pour réaliser un web scraping
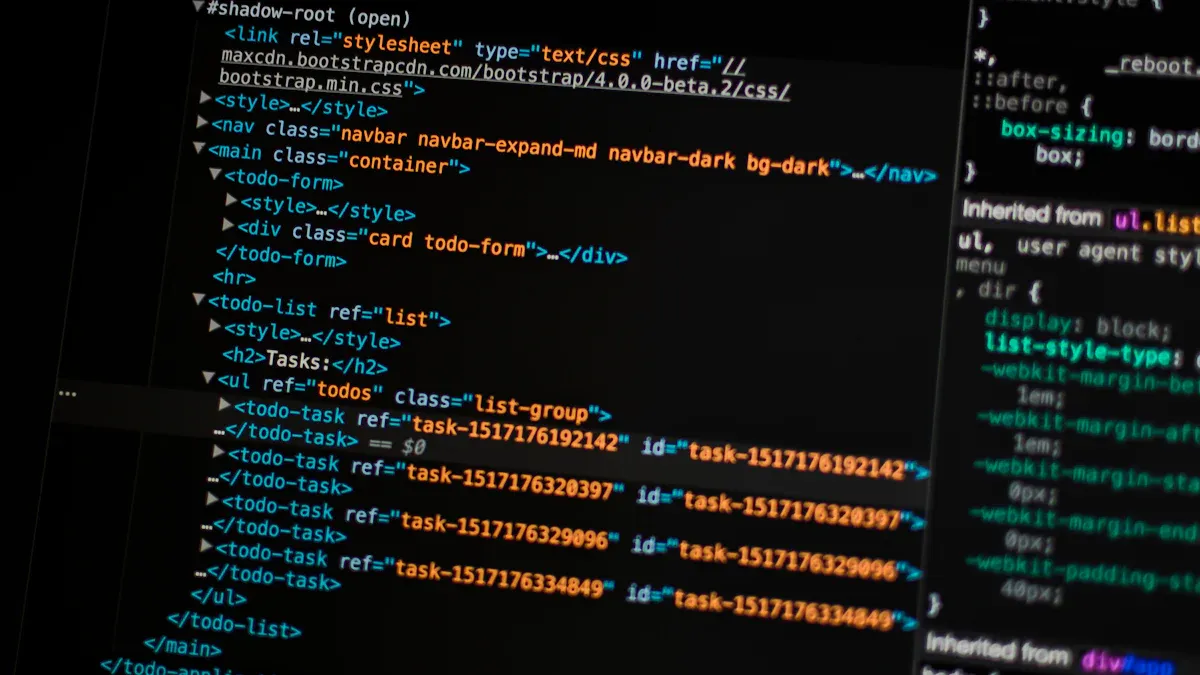
Pour réaliser un web scraping efficace, vous devez suivre des étapes pratiques. Ces étapes vous guideront dans le processus d'extraction de données. Voici comment procéder :
Planifiez votre projet : Avant de commencer, définissez clairement vos objectifs. Que souhaitez-vous extraire ? Cela peut inclure des prix, des avis ou des informations spécifiques sur des produits.
Choisissez vos outils : Utilisez des outils adaptés pour le web scraping. Par exemple, Scrapy et PhantomJS sont des choix populaires. Scrapy est idéal pour des projets complexes, tandis que PhantomJS est utile pour les sites dynamiques.
Créez votre araignée (spider) : Une araignée est un script qui parcourt les pages web. Elle envoie des requêtes pour récupérer les données. Voici un aperçu du fonctionnement d'une araignée :
Le moteur récupère les demandes initiales à parcourir depuis l’araignée.
Le moteur planifie les demandes dans l'ordonnanceur et demande les prochaines requêtes à parcourir.
L'ordonnanceur renvoie les prochaines requêtes au moteur.
Le moteur envoie les requêtes au téléchargeur, en passant par les middleware du téléchargeur.
Une fois que la page est téléchargée, le téléchargeur génère une réponse de la page requêtée et l'envoie au moteur.
Le moteur reçoit la réponse du downloader et l'envoie au spider, en passant par les middlewares d'araignée.
Le spider traite la réponse et renvoie les éléments extraits ainsi que de nouvelles requêtes à suivre au moteur.
Le moteur envoie les éléments traités aux pipelines d'éléments.
Le processus se répète jusqu'à ce qu'il n'y ait plus de requêtes.
Analysez les données : Une fois que vous avez extrait les données, utilisez des métriques de classification non supervisée comme la dissemblance ou la distance pour analyser les résultats. Cela vous aidera à mieux comprendre les données collectées.
Stockez et visualisez : Enregistrez vos données dans un format structuré comme CSV ou JSON. Vous pouvez également créer des diagrammes pour visualiser les résultats. Vérifiez tous les détails du scraper, puis cliquez sur 'Créer un flux de travail' pour voir un diagramme illustrant le fonctionnement du scraper.
En suivant ces étapes, vous maîtriserez le web scraping comment extraire donnees structurees pages web. Cela vous permettra d'extraire des informations précieuses et de les utiliser efficacement.
Considérations éthiques et légales
Lorsque vous vous lancez dans le web scraping, il est crucial de prendre en compte les considérations éthiques et légales. En 2025, les pratiques de web scraping sont encadrées par un cadre juridique en construction au niveau européen. Ce cadre reste controversé et soulève de nombreuses questions.
Voici quelques points importants à considérer :
Droits d'auteur : Les questions juridiques entourant le scraping et le data mining sont essentielles. Vous devez vous assurer que les données que vous extrayez ne violent pas les droits d'auteur. Cela signifie que vous devez respecter les conditions d'utilisation des sites web.
Utilisation des données : L'utilisation des données à des fins commerciales ou de recherche privée soulève des questions éthiques. Vous devez réfléchir à l'impact de votre scraping sur les propriétaires de contenu. Respectez leur travail et leur droit à la propriété intellectuelle.
Consentement : Obtenez le consentement des sites web lorsque cela est possible. Certaines plateformes offrent des API qui permettent d'accéder aux données de manière légale et éthique. Cela vous évite des complications juridiques.
Impact sur les serveurs : Le scraping peut générer une charge importante sur les serveurs des sites web. Évitez de surcharger les serveurs en limitant le nombre de requêtes par minute. Cela montre votre respect pour les ressources des autres.
En résumé, le web scraping peut être un outil puissant, mais il doit être pratiqué de manière responsable. En respectant les droits d'auteur et en utilisant les données de manière éthique, vous pouvez éviter des problèmes juridiques. Pensez toujours à l'impact de vos actions sur les autres. Cela vous aidera à naviguer dans le paysage complexe du web scraping en 2025.
En résumé, vous avez découvert l'importance du web scraping et les raisons pour lesquelles Python est le choix privilégié. Vous avez appris à extraire des données structurées, à utiliser des outils adaptés et à respecter les considérations éthiques.
Pratiquez le web scraping pour améliorer vos compétences. Chaque projet vous aidera à mieux comprendre cette technique puissante.
Explorez davantage les outils disponibles. Voici un tableau comparatif des méthodes de web scraping :
Outil | Coût | Caractéristiques principales |
|---|---|---|
Captain Data | À partir de 100€/mois | Automatisation des tâches, interconnexion avec plusieurs plateformes SaaS |
Scrapy | Gratuit | Framework Python, extensions gratuites, limité pour JavaScript |
LinkClump | N/A | Récupération de liens, facile d'utilisation, limité en fonctionnalités |
Octoparse | Gratuit | Extraction de données sans codage, basé sur le cloud, supporte divers formats de sortie |
ParseHub | Gratuit / Personnalisé | Extraction visuelle, gestion de divers types de contenu web, création d'API |
Continuez à explorer et à expérimenter. Le web scraping peut transformer votre approche des données et enrichir vos projets futurs.
FAQ
Qu'est-ce que le web scraping ?
Le web scraping est une technique qui permet d'extraire des données à partir de sites web. Vous pouvez collecter des informations pour des analyses, des études de marché ou d'autres projets.
Est-il légal de faire du web scraping ?
La légalité du web scraping dépend des conditions d'utilisation des sites web. Respectez toujours les droits d'auteur et obtenez le consentement lorsque c'est possible.
Quels outils dois-je utiliser pour le web scraping ?
Pour le web scraping, utilisez des bibliothèques Python comme Beautiful Soup, Scrapy ou Selenium. Chaque outil a ses avantages selon la complexité de votre projet.
Combien de temps faut-il pour apprendre le web scraping ?
Le temps d'apprentissage varie selon votre expérience en programmation. En général, vous pouvez maîtriser les bases en quelques semaines avec de la pratique régulière.
Quels types de données puis-je extraire ?
Vous pouvez extraire divers types de données, comme des prix, des avis, des informations sur des produits ou des articles de blog. Cela dépend de vos besoins spécifiques.
Voir également
Stratégies Efficaces Pour Traduire Votre Site En 2025
Méthodes Pour Détecter Les Bots Malveillants Sur Votre Site
Nouveautés En Intelligence Artificielle De Google En Février 2025